Poor man's bitemporal data system in SQLite and Clojure
On trying to mash up SQLite with ideas stolen from Accountants, Clojure, Datomic, XTDB, Rama, and Local-first-ers, to satisfy Henderson's Tenth Law. Viz., to make a sufficiently complicated data system containing an ad-hoc, informally-specified, bug-ridden, slow implementation of half of a bitemporal database. Because? Because laying about on a hammock, contemplating hopelessly complected objects like Current Databases isn't just for the Rich man.
Contents
Don't try this at work!
Especially fellow Clojurians trying to realise their Indie B2B SaaS dreams (translation: income and time-poor). Please use a proper professional time-oriented data system. The following are (pithy descriptions mine); and they are available gratis for fledgling commercial use.
- Datomic… "the DB as a value" over an immutable log of all facts.
- XTDB… "the DB as a value" over an immutable log of all bitemporal facts.
- Rama… "any DB as dirt-cheap view" over an immutable log of all events.
Reading Guide / Thinky Thoughts Alert (same thing)
Solitary over-caffeinated temporal database rumination went out of hand. Even The Voices are fed up and want someone to stop us. Furthermore;
- Sage friends already gently shook their heads after hearing The Voices.
- Their hard-won advice—"Just Use Postgres.", and "Please, for everyone's sake, stick with the relational models."—fell on deaf ears. 1
- Obviously, I am also incapable of following my own advice.
Hence this post.
Take what is useful, discard the rest…
The key take-away is: the accountants were right all along. Software engineers will do well, to cleverly copy the accountants 2. Now you may…
- View cat pictures instead.
- Skip to the reference material. Definitely worth your time; pinky promise.
- Skip to Architecture + Code; where the raw rubber tire of one's thinky-thought-ing meets the rough road of relentless Reality.
Or, grab a big beverage to help ingest the ten thousand tokens to follow… Unless you are a Large Language Model. You can't drink. Sucks to be you.
But beware. Once you see, you cannot un-see the fact that…
Any sufficiently complicated data system contains an ad-hoc, informally-specified, bug-ridden, slow implementation of half of a bitemporal database.
— Henderson's Tenth Law.
Factual and Temporal World-Building

Accountants are our exemplary archetype
The cashier at Temporal Convenience Store K9, just handed us our bill. Oi; where is that 10% discount applicable to our bulk purchase of provisions as loyal customers (it's going to be a long trip)?!
Now we think that, but we ask politely, because we know there are many civil ways to sort this snafu without shoplifting or violence. Two universally accepted 3 remedies are:
- The cashier has direct authority to fix it, and they may gladly oblige.
- The cashier's hands are sadly tied. For ERP reasons, accounts alone has authority to issue refunds for bills over a certain value. But we asked nicely so the cashier kindly nods us to accounts, in the backroom.
Odds are that the store people 4 will fix it by issuing two new transactions.
- One transaction to cancel the last bill and reverse the related charge to our spacecard.
- Another transaction issuing the corrected bill, including the discounted amount, with a fresh charge made to our spacecard.
Meanwhile, Temporal Convenience Store K9's various ledgers have received corresponding debits and credits too, of course. But enough. A programmer, though Poor, is no Fool. One does not simply trespass The Field of Accountants. There be dragons.
So… Back to the DB.
One way or another, the store's accounting database must tell these facts:
- At TxTime-7543, Cashier-Adric at Store-K9 ISSUED bill ID-13579 having value 100 spacecoin, and charged it to SpaceCard-1337.
- At TxTime-7587, Cashier-Adric at Store-K9 REVERSED bill ID-13579 having value 100 spacecoin, and refunded it to SpaceCard-1337.
- Maaaybe a note about why it was reversed. 5
- At TxTime-7715, Accounts-Nyssa at Store-K9 ISSUED bill ID-13579-v2 for 90 spacecoin, with a total value of 100 spacecoin minus 10 spacecoin going to discount, and charged 90 spacecoin to SpaceCard-1337.
We call this a temporal data system because it incorporates the passage of time.
- No information is ever modified in-place or deleted.
- New information is always appended.
- To grok the latest state of the accounts, one must read the sequence of all facts recorded in the database.
- Reading a fact updates a separate, current view of the accounts… our "as of now" understanding of the world.
- The "current view" can be rebuilt from scratch, up to any point in time, whether it is "as of now", or "as of last week", or "as of next quarter" (which will be useful only if we add synthetic projected-future events into the database).
So… What to think about in order to design a general-purpose temporal data system that does this for us?
All databases record state of entities
People, things, processes etc. State is the discrete value of some attribute of an entity at a specific point in time.
- Values are timeless and context free
(17). - Attributes provide context
('age'), which we use to suggest and interpret the meaning of a value(= age 17). - Entities are real or imaginary objects (
Adric) having attributes (age).
Thus, the State of Adric can be stated as: Adric's age is 17 as of now.
In a current database—which is just a fancy way of saying database—the as of now is implicit. So is the concept of "age is an attribute of the entity Adric". We just call it Schema, in the abstract.
| entity | age |
|---|---|
| Adric | 17 |
Let's re-state our traditional table as Entity-Attribute-Value (EAV) triplets. Let's also add a column for time (as we often do) to answer questions like "when was Adric's age last updated in our database?".
| entity | attribute | value | time |
|---|---|---|---|
| Adric | age | 17 | as-of-date-time |
From this kernel shall spring forth our world, wrought of facts and time itself. But first, one must acknowledge that…
All the world’s a stage,
And all the men and women merely players;
They have their exits and their entrances,
And one man in his time plays many parts,
His acts being seven ages.— William Shakespeare, As You Like It, Act-II, Scene-VII, Lines 139-143
As my theater gentlefriends like to say…
Everything is Process
We understand the world in terms of processes. All of Reality is a live process which we want to participate in—control, influence, react, adapt. Ergo, all information is part of some process. Yes, even universal constants like c and π, which we can confidently assume to be constant only in our observable universe. Because even these came to be after the moment of the big bang, and will remain only until the eventual heat death of the universe (assuming our universe is ever-expanding, and not a bouncing singularity).
It follows that, to understand the world, we must observe and respond to data; information about various attributes of various meaningful aspects of reality, as we perceive it. Said another way, we understand the world by observing and modifying the state of entities over time—the past, the now, and the later. A person's address, a valve's current position, the remaining free volume of a container, the trajectory of a comet, one's fast-emptying savings account.
| entity | attribute | value | time |
|---|---|---|---|
| Adric | age | 17 | as-of-date-time |
| Adric | address | Foo | as-of-date-time |
| Adric | bitemporal belief | 1 | as-of-date-time |
The more sophisticated a being is, the more context about entities and entity-relationships it is able to keep alive and/or use simultaneously 6.
The identity of an entity is the complete life it lives
Never-ending process is the beating heart, the whistling wind, the pulsing quasar, the furious procreation, the tectonic Subduction, the whispered good-bye, the thermodynamic survival instinct of all things. Process is the why of being. One could even say that an entity without id can have no identity.
This is why, to properly identify an entity, we must egolessly maintain an up-to-date mental-model about it. For that, we must continually observe, record, and aggregate a succession of states of the entity in question.
Consequently, knowledge of entity-attributes alone is not sufficient (Adric has age, address, belief). Knowledge of attribute-values is required too (age is x, address is y, belief is z). And without a sense of time, we simply cannot complete the picture.
To make it concrete:
- Every person's life revolves around their address and we can guess different things about them based on how their address changes.
- You know which Adric is being spoken about because you know
- Adric's age was 17 last year. Adric's age is 18 as of now. Adric's age will be 319 on <specific date>.
- Adric's address was Foo last year. Adric's address is Baz as of now. Adric's address will be Bar after December 2025.
- Adric's belief in bitemporality was 1% last year. Adric's belief in bitemporality is 99% as of now.
- Adric's temporal innocence level was 99% last year. Adric's temporal innocence level is 1% as of now.
- A reader of this set of facts can confidently determine: As-of-now, Adric is an eighteen year old entity that lives at 'Baz', believes strongly in bitemporality, and has nearly no temporal innocence.
| E | A | V | as-of-time |
|---|---|---|---|
| Adric | {:age [:time :years]} | 17 | date-last-year |
| Adric | {:age [:time :years]} | 18 | date-now |
| Adric | {:age [:time :years]} | 319 | date-future |
| Adric | {:address [:text :string]} | Foo | date-last-year |
| Adric | {:address [:text :string]} | Baz | date-now |
| Adric | {:address [:text :string]} | Bar | date-future |
| Adric | {:belief [:bitemporality :%]} | 1 | date-last-year |
| Adric | {:belief [:bitemporality :%]} | 99 | date-now |
| Adric | {:innocence [:temporal :%]} | 99 | date-last-year |
| Adric | {:innocence [:temporal :%]} | 1 | date-now |
KEY: E(ntity), A(ttribute), V(alue)
Having gained this factual understanding, a dear reader may be tempted to further theorise; Adric lost his temporal innocence and eventually ended up living at 'Bar', where he always is these days. Of course, to prove such an allegation, the dear reader would have to piece together many more facts about Adric, and show causation, not mere correlation.
The dear reader may happily play temporal sleuth. However, the temporal database and temporal data engineer are not here to judge. Our role is simply to record the facts as presented, without ego, without prejudice, with integrity, so that the temporal data sleuth may use it productively to figure out what happened, when, and why.
For there is more to facts than meets the eye.
"I'm not in the judgment business, Mr. Orr. I'm after facts. And the events of the mind, believe me, to me are facts. When you see another man's dream as he dreams it recorded in black and white on the electroencephalograph, as I've done ten thousand times, you don't speak of dreams as 'unreal.' They exist; they are events; they leave a mark behind them."
— Dr. William Haber
The Lathe of Heaven, Ursula K. Le Guin.
A fact can be true or false
The temporal sleuth knows that one must resolve the reality of a fact by asserting whether it is true or false.
Our facts table can be expressed as something like the table below. Aspiring temporal data engineers will do well to avoid speculating why a fact might have been asserted true or false. Our ilk must simply realise that we can assert facts this way; <statement of fact> is <true/false?> as of <time>.
Each state of the Adric entity can thus be re-written as an assertion of a fact.
- "Adric's age is 17" is a true fact as of date-last-year.
- "Adric's age is 17" is a false fact as of date-now.
| E | A | V | assert | as-of-time |
|---|---|---|---|---|
| Adric | {:age [:time :years]} | 17 | true | date-last-year |
| Adric | {:age [:time :years]} | 17 | false | date-now |
KEY: E(ntity), A(ttribute), V(alue)
With just this information, the temporal sleuth can infer that Adric's age definitely changed at least once sometime between date-last-year and date-now. But how many times, and to what value, is anybody's guess. For that, we need more temporal observations. Which thickens the plot. For now, we might receive conflicting observations.
What happens when fact and fact collide?
You Won't Believe This One Trick Accountants Use To Deal With Changing Facts. They never delete old entries from their ledgers, they simply make new "correcting entries" (We established this in our motivating example.).
Earlier, we were told to record that the Adric entity's age is 17 as of date-last-year. Presently, we are told to make a note that Adric is NOT 17 any more. We have no idea about Adric's birth date creation date, by the way. We just make a note of assertions of facts about Adric's age, as we are told.
| E | A | V | assert | as-of-time |
|---|---|---|---|---|
| Adric | {:age [:time :years]} | 17 | true | date-last-year |
| Adric | {:age [:time :years]} | 17 | false | date-now |
KEY: E(ntity), A(ttribute), V(alue)
At this point, if anyone asks for Adric's age "as of now", the only truth we can tell is "we don't know". Think about this for a moment. How should we interrogate this temporal data store, to make sense of the information it contains? It's subtle. Hopefully all the thinky thoughting to come will build a clearer intuition. But we are out of time right now…
Sixty seconds later, we are interrupted and told that Adric is in fact 18, and oh by the way, he was already 18 as of date-now. And does it bother us that we wrote the earlier thing down already? No it doesn't. We just assert the new fact.
And just like that…
Now if anyone asks for Adric's age "as of now", we can truthfully answer 18. Because now our table looks like…
| E | A | V | assert | as-of-time |
|---|---|---|---|---|
| Adric | {:age [:time :years]} | 17 | true | date-last-year |
| Adric | {:age [:time :years]} | 17 | false | date-now |
| Adric | {:age [:time :years]} | 18 | true | date-now |
KEY: E(ntity), A(ttribute), V(alue)
Similarly, we make note of other facts about Adric as of various dates on the timeline. But let's add one more key detail… the time at which we made note of the information.
Finally, the Two Questions that put the 'bi' in the 'bitemporal'
Events always occur before they can be recorded. It's just how nature works. Therefore, we can only ever make a note of a fact, after the fact. And so it comes to pass, that any self-respecting temporal sleuth naturally begins their temporal interrogation with two questions:
When did it actually happen?
Only a fact-sender may lay claim to the time an event occurred. And this timestamp must always travel with the fact. Whether the claimed timestamp is acceptable or not is between the fact-sender and the temporal sleuth. The temporal data store and engineer just make sure it is written down exactly as given.
When did we officially record it?
Only the temporal data store—not even the temporal data engineer—may lay claim to when this happened. For the temporal data engineer is just a fallible puny human who can screw up in so many ways. Making typos. Misreading the clock. Lazily avoiding recording facts until the auditor comes a-calling. Or even forgetting the fact entirely, upon discovery of which fact, the temporal sleuth gets called in to piece together what might have happened.
So, let's update our temporal data table with the "transaction" time, at which the data store guarantees that it has immutably inscribed a fact.
To ease table-reading life of our fellow our puny humans, we also rearrange the time columns a bit. Now, we can manually read records as follows:
- At Transaction Time
t02, the table recorded the following fact:- As of
dt-now,Adric's:agebeing17stands REDACTED.
- As of
- At Transaction Time
t03, the table recorded the following fact:- As of
dt-now,Adric's:agebeing18stands ASSERTED.
- As of
| tx-time | as-of-time | E | A | V | assert |
|---|---|---|---|---|---|
| t01 | dt-last-yr | Adric | {:age [:time :years]} | 17 | true |
| t02 | dt-now | Adric | {:age [:time :years]} | 17 | false |
| t03 | dt-now | Adric | {:age [:time :years]} | 18 | true |
| t04 | dt-future | Adric | {:age [:time :years]} | 319 | true |
| t05 | dt-last-yr | Adric | {:address [:text :string]} | Foo | true |
| t06 | dt-now | Adric | {:address [:text :string]} | Bar | false |
| t07 | dt-now | Adric | {:address [:text :string]} | Baz | true |
| t08 | dt-future | Adric | {:address [:text :string]} | Bar | true |
| t09 | dt-last-yr | Adric | {:belief [:bitemporality :%]} | 1 | true |
| t10 | dt-now | Adric | {:belief [:bitemporality :%]} | 99 | true |
| t11 | dt-future | Adric | {:belief [:bitemporality :%]} | 0 | false |
| t12 | dt-last-yr | Adric | {:innocence [:temporal :%]} | 99 | true |
| t13 | dt-now | Adric | {:innocence [:temporal :%]} | 1 | true |
| t14 | dt-future | Adric | {:innocence [:temporal :%]} | 33 | false |
KEY: E(ntity), A(ttribute), V(alue)
This brings us to the absurdity of time travel… For things to get better, they have to get weird first.
Reality versus (data-based) Time-Travel

"Why do you think your mother didn't notice that reality had changed since last night?"
[Dr. Haber]"Well, she didn't dream it. I mean, the dream really did change reality. It made a different reality, retroactively, which she'd been part of all along. Being in it, she had no memory of any other. I did, I remembered both, because I was… there… at the moment of the change. This is the only way I can explain it, I know it doesn't make sense. But I have got to have some explanation or else face the fact that I'm insane."
[Mr. Orr]
The Lathe of Heaven, Ursula K. Le Guin.
Actual Time Travel is different each time, because the very act of it interacts with and perturbs Reality. Not being higher dimensional beings, we have evolved to get by, by perceiving very little of very little. To us, convenient fictions are good enough Reality.
No temporal database can contain Reality itself
"The Song" is a convenient fiction.
We love to loop a favourite hit single. Yet…
- A record is not "The Song". All recordings are lossy 7 because all acts of measurement are lossy. That's just physics.
- A replay is not "The Song". Every replay is the same information yet it is new, because Reality is ever-moving, ever-changing. (Ignoring for a moment the fact that every replay degrades the storage medium—vinyl, compact disk, copper plate, SSD—causing further information loss.)
- Nor are live performances "The Song". Each rendition is different.
Similarly, temporal databases can only mimic Time Travel.
- The experience of Reality can only ever be captured as finite, discrete observations (samples and measurements).
- Therefore, a temporal recording or database can only ever contain approximate observations of Reality.
- Each time we retrieve the observations, we cannot help but reinterpret them because we ourselves have changed in the interval.
We can only ever sing songs about what we believed happened.
Reality transpires in Dedekind cuts
"This Instant" is a convenient fiction.
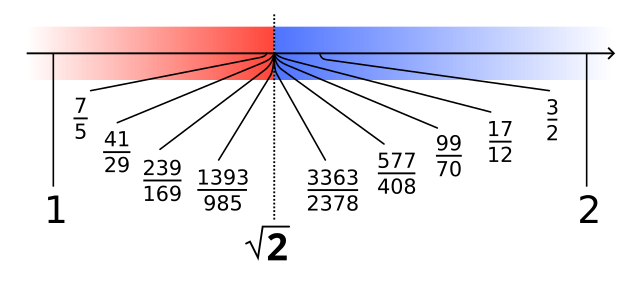
Every observation of reality exists somewhere inside of an interval, because our means of measurement can only ever approximate the moment of occurrence of an event. The idea of the Dedekind Cut frames this neatly.
A Dedekind cut is a partition of the rationals Q into two subsets A and B such that
Ais nonempty.A ≠ Q(equivalently,Bis nonempty).- If
x,y ∈ Q,x < y, andy ∈ A, thenx ∈ A. (Ais "closed downwards".) - If
x ∈ A, then there exists ay ∈ Asuch thaty > x. (Adoes not contain a greatest element.)
By omitting the first two requirements, we formally obtain the extended real number line.
{kind=link}
Why split such philosophical hairs? Why?
Because, we must record temporal facts with proper temporal resolution. For example, an infinitesimal such as a Femtosecond (10-15s) can be…
- Just Right… for that "Femto Laser" Cataract removal or LASIK surgery.
- Waaay over the top… for orchestral arrangements where sub-millisecond (< 10-3s) coordination is more than enough.
- Or too coarse(!)… for Quantum dynamics studies, where incredible things happen in attoseconds (10-18s). 8
More subtly, because all Temporal Data Processing queries are Interval queries, served by collating facts that happened starting Time X to Time Y.
For example, "Calculate the state of the world as-of some Instant."
To serve this query, we must collate all facts starting from the earliest available ones, right up to whatever as-of time Instant. It could be as-of <some past moment>, or as-of some projected future, or…. as-of this very instant, a.k.a. a now query.
The now query is a special-case as-of query, because now is an expanding query window… ever-increasing "wall-clock time". It means our computer's temporal resolution, which the temporal database relies on, must suit that of incoming facts. My cheap wristwatch will botch your Formula One lap times.
Fun fact: The now query returns a Current Database.
Facts contain observations. Observations are not Reality.
"Facts" are a convenient fiction.
To fact-find, we must observe. Observation requires measurement. Measurements are inherently lossy. Consequently, no collection of facts, no matter how fine-grained can ever capture Reality as it actually happened.
Besides, facts depend on who's observing. Having experienced the world a bit, we have doubtless realised that, routinely…
- The same party told us "use this fact", at different times, with no regard to whatever happened in-between.
- OR, it's possible that the same party sent us two different facts at the same time, but they were recorded in the table at different times. Maybe the temporal database recorded one fact, but before it could record the other fact, it got waylaid by a VACUUM emergency. It happens.
- OOOORRRR, it is possible that two different parties with different vantage points of a shared reality sent their observations independently, without being aware that other party even exists. Our temporal database just says "okay then", and records both claims of facts about observed reality.
As we established in the Adric scenario, multiple facts for the same E-A-V triple, can claim to have occurred at the same time (Adric is NOT 17 as-of-now, and Adric IS 18 as-of-now).
Consequently, though our bitemporal database notes down distinct facts at different times, we cannot presume that the sequence of recording follows Reality.
In other words…
Facts are mutually independent parallel claims that assert or redact some aspect of concurrent real-world events.
In fact, facts are always so. Variables are mutually dependent or independent; correlated or uncorrelated, because variables subsume Real identities, all of which live in the contiguous fabric of the same shared Universe.
What the Fact?!
Materialised "Reality" depends on who's asking.
"Reality" is a convenient fiction.
We simulate alternate reality all the time. Worrying about the future. Worrying about what someone must be thinking about us just now. Questioning past life choices and wondering "what if". Much like financial analysts, weather modelers, chess pros, special ops teams running scenarios and doing retrospectives. Except those other people get paid to imagine worst case scenarios.
- If each fact lives on its own conceptual timeline, then we must necessarily reconstruct reality by threading a point of view through a sequence of recorded facts.
- Only the temporal sleuth—not the temporal database, nor engineer—get to choose which timeline or timelines (sequence(s) of facts) ought to construct a prospective Reality.
- Only the temporal sleuth gets to choose the
as-ofpoint in time wherefrom to do so—now, past, future; separately or simultaneously. And gets paid to imagine alternate realities.
Architecture Decisions + Code

nb. All code snippets are Clojure. All SQL is written specifically for SQLite, using the Honey SQL library (SQL as Clojure data structures).
The Bet
All data systems are, in reality, temporal data systems. Most just don't know it until it's too late. Things—as life teaches inevitably—have a habit of getting real, real fast. Suddenly, one fine day, life will deliver us a forehead-slapping moment because even that tiny-SaaS indie B2B app has manifested "a sufficiently complicated data system". Because complexity is inevitable.
The Architecture: A Vertically Integrated SaaS Machine
Runaway incidental complexity of software is why computers got slower while hardware and networks got faster. This bothers me no end. I want to profit from the glut of compute without taking on systemic complexity. 9
One way is to build software applications as unified vertically integrated computer systems, as a fruit-named company famously does. And, as is true for contemplating complected objects on hammocks, profiting from full-systems vertical integration isn't just for the absurdly rich global conglomerate.
nb. "Vertical Integration" does NOT mean "Being Rigid". Quite the opposite; it means cultivate total adaptability, situational awareness, and mastery over self and environment. 10
The Trade-Off: Hard to design, Easy to Build-Own-Operate-Teach
The main thing to understand is that changing any single detail of a vertically-integrated system could mandate ripple-effect changes through the whole system… and that is okay.
The indie vertically-integrating systems builder should choose an extreme position:
- Either go all-in on a single all-encompassing web SaaS stack (application framework, server runtime, tool chain).
- Or make a custom system of composable parts. Entirely avoid building on top of pre-designed monolithic frameworks (most Clojure pros).
Either way is fine. Either way demands significant investment from the committed indie SaaS builder. The only real choice one has, is to own it—learn to fit self to it, or make it fit to self. 11
Above All: Aggressively Minimise System-Wide Complexity
The absurdly not-rich local indie SaaS maker must accept the complexity-management limits of their own smol brain. And that is okay. One poor brain can do a lot, if it asks "So, like, how do I build a unified, coherent system specialised to me—my goals, needs, and indeed, to my way of thinking?", which is…
- no cloud services lock-in (no VC funding. no funding at all, actually.)
- no framework lock-in (a-la-carte pieces)
- no tool-bench / process lock-in (design own tools shaped for own brain)
- no devops clones (dead-simple deployments, observability, failover etc.)
- no (future) customer data lock-in (must be local-first compatible)
Well, I am a grug-brained developer 12 therefore "the system" must be small conceptually, and literally. It is mission-critical to build the system piecemeal, where we intimately know the parts and can fully control interfaces between parts and abstraction boundaries.
In the context of a SaaS web application it means:
- Single-server installation
- App, db, cache, queue, document store, server, proxy; everything on one box
- To scale, beef up server
- Unified Application + Database architecture
- In-process databases only
- Universal, static, zero-migration storage schema
- All application-specific materialised views as application code i.e. the application is not "just a DB wrapper".
- Optionally, single tenancy. One DB per tenant, for regional compliance, and horizontal scaling as a nice side-benefit.
- No write concurrency. All database operations are one-way loops.
- No "Distributed Local-first". Local-first mode is unauthenticated single-user. Server-mode is bog standard synchronous SaaS.
- Immutability by default
- idempotence where immutability gets too involved to implement correctly
- in-place mutation only as a rare, purposeful, escape hatch when both immutability and idempotence get too complex or too resource-hungry
- idempotence where immutability gets too involved to implement correctly
- One DB Engine to rule them all
- Primary store
- K/V store
- Sessions store
- Cache
- Document store
Two Wee VMs, please. One to serve, one for failover.
Seriously.
Computers today—even the cheap shared VMs—are stupid-fast. A properly built web app can use the smallest VM below, to support a healthy SaaS business, with room to grow. Add one more box on hot standby for failover.
| Name | VCPU | RAM | NVMe SSD | Traffic incl. IPv4 | Hourly | Monthly |
|---|---|---|---|---|---|---|
| CX22 | 2 | 4 GB | 40 GB | 20 TB | € 0.006 | € 3.79 max. |
| CX32 | 4 | 8 GB | 80 GB | 20 TB | € 0.0113 | € 6.80 max. |
| CX42 | 8 | 16 GB | 160 GB | 20 TB | € 0.0273 | € 16.40 max. |
| CX52 | 16 | 32 GB | 320 GB | 20 TB | € 0.054 | € 32.40 max. |
Source: hetzner.com, as-of 2025-07-12. No affiliation.
Wherever it's up to me, I will just keep beefing up that single-box installation, for as long as I can get away with. Max out normie VMs with taxing DB queries of a hacked-up temporal database, used by a bog-standard JVM web app.
Like, if I were a web app, that CCX63 would feel absolutely palatial.
Gimme it! 13
| Name | VCPU | RAM | NVMe SSD | Traffic incl. IPv4 | Hourly | Monthly |
|---|---|---|---|---|---|---|
| CCX13 | 2 | 8 GB | 80 GB | 20 TB | € 0.02 | € 12.49 max. |
| CCX23 | 4 | 16 GB | 160 GB | 20 TB | € 0.0392 | € 24.49 max. |
| CCX33 | 8 | 32 GB | 240 GB | 30 TB | € 0.0777 | € 48.49 max. |
| CCX43 | 16 | 64 GB | 360 GB | 40 TB | € 0.1546 | € 96.49 max. |
| CCX53 | 32 | 128 GB | 600 GB | 50 TB | € 0.3085 | € 192.49 max. |
| CCX63 | 48 | 192 GB | 960 GB | 60 TB | € 0.4623 | € 288.49 max. |
Source: hetzner.com, as-of 2025-07-12. No affiliation.
Feed cheap disks to storage-hungry Temporal Databases
Current Databases terrify the temporal database engineer. A current database is a giant mass of global mutable state. It has no innate sense of time. And current database engineers inevitably have to manage concurrency. Some even have to delve into the dark arts of Multi Version Concurrency Control. 14
This mortal fear causes temporal database designers to copy accountants, who have been doing temporal data engineering for centuries. Why not tackle the far simpler problem of making everything append-only? Make a DB engine which will guarantee that at such-and-such time it faithfully recorded <this set of claimed facts>, as-given, nondestructively.
However, copying accountants isn't free.
- For one, temporal databases hoard data; chomping Terabytes for breakfast. The stuff of DB-tuning nightmares of current data engineers.
- For another, without the right tools, we risk being Disk-wise but Query-foolish. We mitigate this by copying architects (of software).
Here are some worth copying.
Clojure: Namespaces and Immutability are honking great ideas
We want to constrain all entities to well-known, guaranteed globally-qualified namespaces. So…
worldis the only global namespace we permit, and is also the only single-segmented namespace- all other namespaces must be minimum two-segmented, such as
com.acmecorporcom.acmecorp.foo-client. ns_namemust only ever be the namespace part (such ascom.acmecorporworld) of a fully qualified entity name (ofcom.acmecorp/userorworld/administrator).
All SQL is written for SQLite, using Honey SQL by Sean Corfield.
SQL as Clojure data structures. Build queries programmatically – even at runtime – without having to bash strings together.
HoneySQL: Constrain World Namespaces

{:create-table [:world_namespaces :if-not-exists]
:with-columns
[[:rowid :integer :primary-key]
[:ns_name
:text [:not nil] [:unique]
[:check [:and
[:= :ns_name [:trim :ns_name]]
[:= [:text_split :ns_name "/" 2] ""]
[:or
[:= :ns_name "world"]
[:<> [:text_split :ns_name "." 2] ""]]]]
;; somehow we must enforce these names are globally unique
]
[:is_active :boolean [:not nil] [:default false]
;; sometimes a namespace may be deactivated but kept around
]
[:is_deleted :boolean [:not nil] [:default false]
;; true IFF the namespace *and every bit of its data*
;; was permanently erased
]
[:ns_meta :text
;; semi-regular information about the namespace / org.
;; {:org-name "ACME Corp."
;; :address {:street "001"
;; :city "Eta Omega" ... }}
]]}
HoneySQL: Constrain World Users

All users must ID as fully-qualified name like com.acmecorp/adi, following the constraint of standard global namespacing (some.name.space/the-name).
{:create-table [:world_users :if-not-exists]
:with-columns
[[:rowid :integer :primary-key]
[:ns_user_id
:text [:not nil] [:unique]
[:check [:= :ns_user_id [:trim :ns_user_id]]]]
[:ns_name
:text [:not nil]
:generated-always :as [[:text_split :ns_user_id "/" 1]]
:stored]
[:user_name
:text [:not nil]
:generated-always :as [[:text_split :ns_user_id "/" 2]]
:stored]
[:user_type :text [:not nil] [:default "UNSPECIFIED"]
;; call it "user_type", symmetric with "entity_type",
;; because users are special case entities
;; :system/owner, :system/admin, :system/member, :system/bot
;; :org/owner, :org/admin, :org/member :org/bot
]
[:is_active :boolean [:not nil] [:default false]
;; sometimes, a user may be deactivated
;; but kept around for <reasons>
]
[:is_deleted :boolean [:not nil] [:default false]
;; signal that user and /every bit of user data/
;; was permanently erased
]
[:ns_user_meta :text
;; semi-regular information about the user
;; {:first_name "Foo" :last_name "Bar"
;; :address {:flat "001" :city "Lambda" ... }}
]
[[:foreign-key :ns_name]
[:references :world_namespaces :ns_name]
;; We would like to strictly permit
;; only pre-registered global namespaces.
]]}HoneySQL: Constrain World Entities
Entity namespacing is according to the global standard—some.name.space/the-entity-name—constrained by our namespaces schema. So entity IDs could be: com.acme/adi,
com.acme/file, com.acme/category, com.acme/tag, com.acme/user-role.
{:create-table [:world_entities :if-not-exists]
:with-columns
[[:rowid :integer :primary-key]
[:ns_entity_id
:text [:not nil] [:unique]
[:check [:= :ns_entity_id [:trim :ns_entity_id]]]
;; com.acme/adi, com.acme/file, com.acme/category
;; com.acme/tag, com.acme/user-role
]
[:ns_name :text [:not nil]
:generated-always :as [[:text_split :ns_entity_id "/" 1]]
:stored
;; com.acme
]
[:entity_name
:text [:not nil]
:generated-always :as [[:text_split :ns_entity_id "/" 2]]
:stored
;; adi, file, category, tag, user-role
]
[:entity_type
:text [:not nil]
[:default "UNSPECIFIED"]
;; ":user/actor" ":user/role" ":content/file"
;; ":content/category" ":content/tag"
]
[:is_active
:boolean [:not nil]
[:default false]
;; sometimes a entity may be deactivated but kept around
]
[:is_deleted
:boolean
[:not nil] [:default false]
;; signals that entity and all entity data may be garbage-collected
]
[:ns_entity_meta :text]
[[:foreign-key :ns_name]
[:references :world_namespaces :ns_name]]]}Datomic: Single-thread writes, concurrent reads
SQLite in WAL mode is the poor man's single-computer Datomic—one sequential writer, many concurrent readers, mutually non-blocking, with globally atomic transactions. To be clear, Datomic itself can be the poor man's single-computer Datomic. Ditto for XTDB and Rama. Clojure programmers will do well to study the Clojure agent primitive, to build a good mental model about SQLite in WAL mode.
Code: SaaSy SQLite Configuration
Some recommended PRAGMA settings to use SQLite as a web backend.
{:dbtype "sqlite"
;; INCREMENTAL = 2. Set manually. Not supported by xerial.
:auto_vacuum "INCREMENTAL"
:connectionTestQuery "PRAGMA journal_mode;" ; used by HikariCP
:preferredTestQuery "PRAGMA journal_mode;" ; used by C3P0
;; :maximumPoolSize max-concurrency ; not supported by Xerial
:dataSourceProperties
{:limit_worker_threads 4
:enable_load_extension true ; disabled by default for security
:busy_timeout 5000 ; ms, set per connection
:foreign_keys "ON" ; ON = boolean 1, set per connection
:cache_size -50000 ; KiB = 50 MiB, set per connection
:journal_mode "WAL" ; supported by xerial JDBC driver
;; NORMAL = 1, set per connection
:synchronous "NORMAL"}}* nb. Some PRAGMAS are set at the DB level, and others are set on a per-connection basis. I'm using HikariCP connection pooling library to help me do this cleanly (paired with xerial's JDBC driver for SQLite).
However, I might be able to drop HikariCP… the spirit of "fewer dependencies, better life" is hard to ignore. Just look at Anders Murphy's neato work on hyperlith ("the hypermedia based monolith", using Datastar and Clojure), and sqlite4clj. See the hyperlith examples, particularly OneBillionCells: code, demo. Rad!
XTDB: All facts are bitemporal by design
The full, faithfully recorded, append-only log of world facts, as claimed by any of the pre-registered users, about any of the pre-registered entities, belonging to pre-registered namespaces.
HoneySQL: Our central append-only "World Facts" table
{:create-table [:world_facts :if-not-exists]
:with-columns
[[:rowid :integer :primary-key]
[:txn_id :numeric [:not nil]
;; MUST be a uuidv7
]
[:valid_id
:numeric [:not nil]
:unique [:default [[:uuid7]]]
]
[:txn_time
:numeric [:not nil]
:generated-always :as [[:uuid7_timestamp_ms :txn_id]]
:stored]
[:valid_time
:numeric [:not nil]
:generated-always :as [[:uuid7_timestamp_ms :valid_id]]
:stored]
[:valid_preferred
:boolean [:not nil]
[:default false]
;; use this /mutably/ to resolve conflicting valid timelines
]
[:e :text [:not nil]] ; Entity
[:a :text [:not nil]] ; Attribute
[:v :numeric] ; Value
[:assert :boolean [:not nil]]
[:ns_user_ref :numeric [:not nil]]
[:fact_meta :numeric
;; Use this to /mutably/ attach auditor notes to history data.
;; Maybe track addition of the auditor note as a new fact.
]
[[:foreign-key :ns_user_ref]
[:references :world_users :ns_user_id]
;; Permit facts only from known, pre-registered users.
[:foreign-key :e]
[:references :world_entities :ns_entity_id]
;; Permit facts only about known, pre-registered entities.
]]}Realities are arrows. Time marks flight. UUIDv7 is Time.
Processes are happening. Facts are being recorded. Events occur along a virtual timeline, not a physical one.
Instead of compositing a physical time and a virtual ID into one identifier, why not use a virtual time-is-a-vector style identifier and derive physical time from it for use in our normal day to day SQL queries, in addition to also having an identifier that is a standard requiring no coordination to create, is globally conflict-free, and is SQL DB indexing-friendly as well as query-friendly? In a world where disks are cheap, and data generation is unlimited, we can afford to waste computer resources on giant IDs instead of compact little Integers that overflow.
UUIDv7 helps us express this concept. This is crucial for conflict management.
Our system relies on the guarantee that valid_id is globally unique, even when the UNIX time component of valid-id for multiple colliding facts is the same.
The default decision heuristic is "latest asserted fact wins". The "last write wins" principle is popularly used by the local-first community too (e.g. in CRDTs).
Of course, this thumb rule is not always acceptable. Humans will disagree about the facts for un-computable reasons.
For example, different editors at the publisher Target may lay different claims to the same titular character name: claim conflicting values, and/or different asserted states. Now they have to duke it out and decide which assertion or redaction should apply for that EA pair at a given physical time.
valid_ID |
e | a | v | owner_ref |
|---|---|---|---|---|
| 01978840-4816-787c-8aab-d39bd088754b | character-id-42 | character/name | The Tenth Doctor | com.target/editor-alpha |
| 01978840-4816-787c-8efg-r8235asdf3rb | character-id-42 | character/name | Dr. Who | com.target/editor-bravo |
| 01978840-4816-787c-098a-757o8ujygasf | character-id-42 | character/name | The Doctor | com.target/editor-charlie |
The tie-break may be "We compromise on this particular version of facts""
select * from world_facts
where valid_id = '01978840-4816-787c-8aab-d39bd088754b';"We break the tie in our world_facts table, using a boolean column, valid_preferred. We allow in-place updates to this field because that makes life simpler. Alternative tie-break choices:
- "We hereby decree that such-and-such is the preferred version of the facts to use for all as-of queries."
update world_facts set valid_preferred = 1
where valid_id = '01978840-4816-787c-8aab-d39bd088754b';- "First dibs wins", based on the transaction ID of the E/A pair.
update world_facts set valid_preferred = 1
where e = 'character-id-42' and
a ='character/name' and
txn_id = '01978840-4816-787c-8aab-d39bd088754b';- "Only use Charlie's choice names for the character; henceforth and retroactively."
update world_facts set valid_preferred = 1
where e = 'character-id-42' and
a ='character/name' and
owner_ref = 'com.target/editor-charlie';nb. A proper setter query must ensure valid_preferred is set to true for exactly one world_fact, in a set of disputed colliding facts. And it should append a new world_fact, stating for the record, that such-and-such valid_id was set to valid_preferred =
true at such-and-such time, by such-and-such user.
HoneySQL: Current DB is just a VIEW of valid World Facts as-of-now
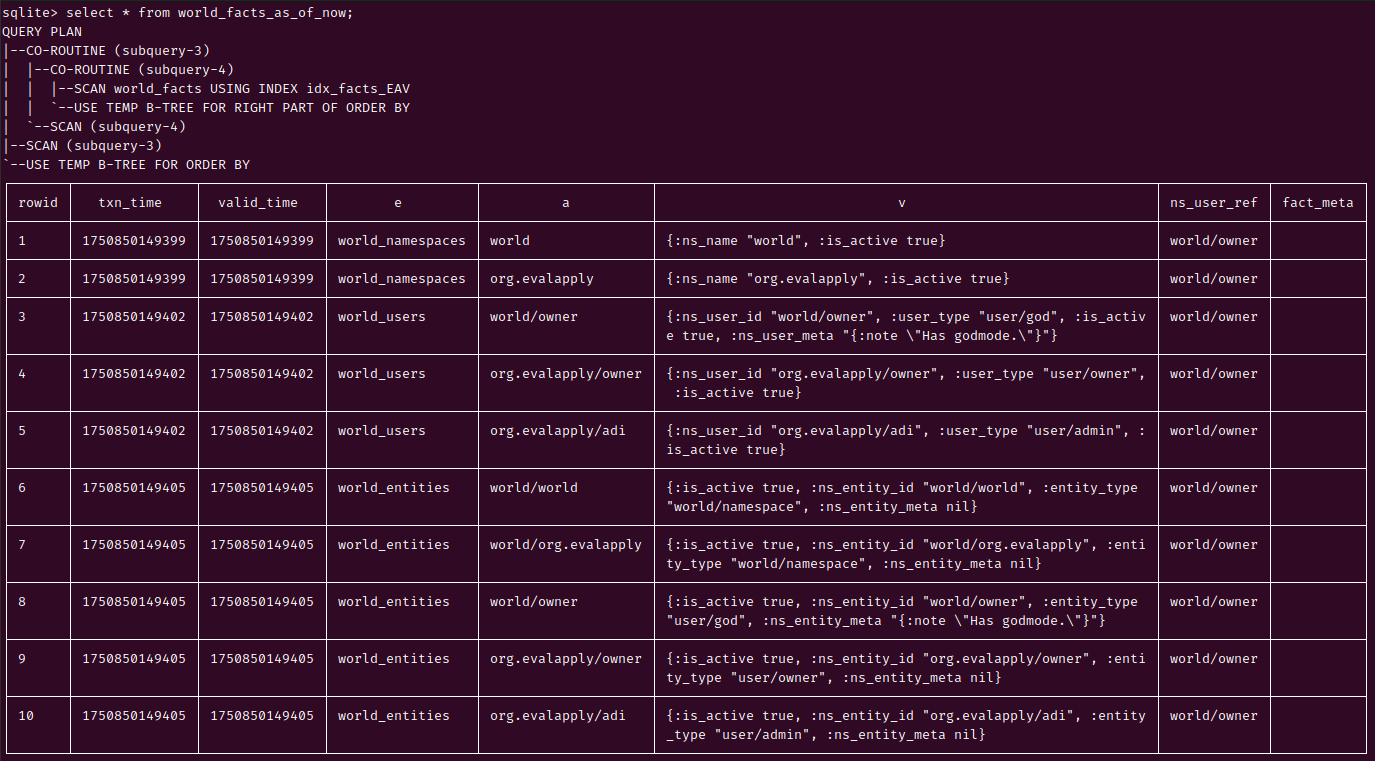
SQLite's window queries are handy!
{:create-view [:world_facts_as_of_now :if-not-exists]
:select [:rowid
:txn_time :valid_time
:e :a :v
:ns_user_ref :fact_meta]
:from {:select [:*
[[:over
[[:row_number]
{:partition-by [:e :a],
:order-by [[:valid_preferred :desc]
[:txn_id :desc]]}
:row_num]]]]
:from :world_facts}
:where [:and [:= :row_num 1] [:= :assert 1]]
:order-by [[:rowid :asc]]}
HoneySQL: Current DB: Indices and Full Text Search for great good
The DDLs are elided because they are boring.
Indices: Basically, we may create reverse indices of Facts, to support query patterns, as needed. Some possible indices for day-to-day "online" use, to be created on the "current world facts" view.
- EAV: Entity, Attribute, Value
- EAVTx: EAV, TransactionTime
- AEVTx
- AVETx
- VxAETx: ValidTime, AETx
Normally, we wouldn't want to touch our lynchpin "World Facts" table. Indices consume disk space and that table will grow fast. The same indices might be required for retroactive "audit" use cases. Ideally I would do this sort of querying "offline", against a snapshot of the primary DB.
For Full Text Search, I intend to use SQLite's built-in 'FTS5' extension. It requires a bit of SQL writin'—make a Virtual Table, and then write a bunch of Triggers to keep it up-to date. Again, very boring SQL, well documented at the extension's page. It just needs writing, is all.
Something like this…
(defn search-world-facts-as-of-now
"Run the given search query against the FTS table and
return a match from the original world_facts table."
([where-search-clause-raw-sql]
(search-world-facts-as-of-now
(partial format "fts_world_facts_as_of_now MATCH %s")
where-search-clause-raw-sql))
([search-term-formatter where-search-clause-raw-sql]
(hsql/format
{:select [:world_facts.*]
:from [:fts_world_facts_as_of_now]
:join [:world_facts
[:=
:fts_world_facts_as_of_now.rowid
:world_facts.rowid]]
:where [:raw (search-term-formatter
where-search-clause-raw-sql)]
:order-by [:rank]}
{:inline true})))Rama: Views are just data. Materialize in Clojure. Not in SQL.
The temporal database does not discriminate when storing facts. Consequently, any given temporal database could contain any of…
- At least a partial snapshot of at least one Reality,
- OR several partial snapshots of one Reality,
- OR several partial snapshots of several, possibly alternate and parallel, Realities.
The great power (and great responsibility) to decide the concretely materialised reality of the world resides solely in the hands of the party interrogating the temporal database.
Therefore, the temporal database designer must create interrogation tools (query languages, data storage and access formats etc.) so the temporal data engineer can sift through a veritable multiverse, to figure out what "the world" looked like as of whatever time interests them.
I have been warned that attempting temporal queries with SQL will cause obnoxious joins, strange indexing schemes, finicky triggers, stored procedures from hell, and non-standard shenanigans specific to the database engine in question. 15.
See James Henderson's "Building a Bitemporal Index" series—parts one, two, and three—to get a flavour of temporal query patterns that challenge current databases as well as current data engineers. Haunting questions like Why do you need to use a database with bitemporality baked in anyway?
Fortunately, if we play our cards right, this all-you-can-eat pedantic fact-recording can help us create truly general-purpose data systems. For example, Specter is a critical piece of Rama's query infrastructure, allowing the system to cheaply query materialised views.
A lot of Rama programming revolves around materializing views (PStates), which are literally just data structures interacted with using the exact same Specter API as used to interact with in-memory data structures. This stands in stark contrast with databases, which have fixed data models and special APIs for interacting with them. Any database can be replicated in a PState in both expressivity and performance, since a data model is just a specific combination of data structures (e.g. key/value is a map, column-oriented is a map of sorted maps, document is a map of maps, etc.).
We will embed all on-demand views in code, using plain ol' Clojure transducers and/or Specter's capabilities.
This endows our vertically integrated tiny-SaaS system with the Poor Man's cheap copy of Rama's task model of distributed programming.
- Views always travel with the web application.
- The database is always in-process.
- The data file itself is always machine-local.
- Each tenant gets their own dedicated SQLite database.
Further, it means that migrations occur NOT by futzing with database schemas, but by rolling out a new version of application code.
So, if the database architecture and schema never changes, and I don't screw up writing to it, then I should never ever need to run a schema migration. In the off-chance that I do need to physically migrate schema, I will be forced to do it in an append-only way, because that's how SQLite data migrations work the best and safest. Which is a good corner to box oneself into, because it forces us to do nondestructive migrations, be they of schema or of data. This makes gradual roll-outs and complete roll-backs fairly safe.
SQLite has one more compelling feature.
SQLite: Flexible typing for the win
Without this, the Facts table would be rather ungainly. With flexible typing, our 'numeric' values are stored as efficiently as they can be stored. Numbers are stored as numbers. Text is stored as text. Booleans are stored as booleans. In the very same column.
However, it does not protect us the way Datomic, XTDB, and Rama do. We have to make our own guardrails to safely use SQLite as if it were a temporal database.
- Work against a strictly constrained world (namespaces, users, entities)
- Emulate immutability for the most part (append-only facts).
- Use Idempotence (upsert entities -> facts)
- Facts must include all actions happening within the world, including addition, removal, updates to namespaces, users, entities, fact meta-data, and set-preferred-fact choices.
Something like this…
Transact Facts: Append-only
(defn append-facts!
([tx facts]
(append-facts! tx facts nil))
([tx facts owned-by-ns-user-id]
(jdbc/execute! tx
(-> facts
(insert-world-facts-hsql
owned-by-ns-user-id)
hsql/format))))Transact Entities, Namespaces, Users Idempotently
And append corresponding facts in the world-facts table too. Yes, it doubles up as an audit log for things that were done to the World itself, in addition to things happened inside the World.
(defn transact-entities->facts
[tx entity-records fact-data]
(and (seq (upsert-entities! tx entity-records))
(append-facts! tx
(transduce
(record->fact-xf "world_entities"
:ns_entity_id
fact-data)
conj []
entity-records))))
(defn transact-namespaces->entities->facts
[tx ns-records fact-data]
(and (seq (upsert-namespaces! tx ns-records))
(append-facts! tx
(transduce
(record->fact-xf "world_namespaces"
:ns_name
fact-data)
conj []
ns-records))
(transact-entities->facts tx
(ns-records->entity-records
ns-records)
fact-data)))
(defn transact-users->entities->facts
[tx user-records fact-data]
(and (seq (upsert-users! tx user-records))
(append-facts! tx
(transduce
(record->fact-xf "world_users"
:ns_user_id
fact-data)
conj []
user-records))
(transact-entities->facts tx
(user-records->entity-records
user-records)
fact-data)))One more cool thing about SQLite is that it can totally be used as our "Everything DB Engine" (see: oldmoe/litestack), with purpose-specific database files (queue, cache, sessions, documents, key-value store). SQLite's ability to do cross-database joins will doubtless come handy too.
Git and Local-First: Somehow make all facts merge
A fact is a snapshot of an event in time. If we are careful to send facts around so that they are trivial to merge in a facts table, then we can separate out conflict management. Git shows the way. When we fetch changes, the objects are synced to our computer. If a conflict occurs, then what happens to the objects? They remain cached on disk. Git simply refuses to transact the conflict into the live state of the codebase, until someone a) fixes the conflict manually and b) tells git that the conflict is resolved. Git does not know or care about the conflict resolution mechanism. This is because conflicts occur due to essential tacit and implicit context that never travels with the objects. Disambiguation thus requires converging on shared agreement, which is a squishy non-deterministic process at best, chaotic and interminable at worst. Have you heard of laws and lawmakers?
TODO: Production engineering things one ought to do
Things like…
- Tests for write integrity
- See if we can use spec / malli to generatively test this
- Model an example domain of sufficient complexity
- A single example customer (presuming a tenant per DB)
- All their users
- All their workflows
- All their data
- Offload complex joins to the app (specter)
- But only a pre-filtered subset lifted from the database
- The
world_factstable is going to grow very fast. Measure latency at various orders of magnitude, for the same example domain complexity, for the same line-of-business read/write pattern (SaaS-y 80% read, 20% write, for example).- 1 M facts
- 10 M facts
- 100 M facts
- 1000 M facts
- etc…
Basically, try to find out all the ways this will fail to satisfy the "can I get away with it" criterion.
Postamble / Rant As A Recap (same thing)
A gaggle of reasons 16 diverted me onto this long road to a small mangy database 17.
- wannabe be an Independent Software Vendor,
- specialised in building niche SaaS products,
- operating on dirt-cheap server infrastructure,
- with super-duper low maintenance overhead,
- while being able to extend the SaaS to local-first usage 18
As a consequence:
- Most crucially, I must design and build a system that I can hold in my head and explain to anyone. It is a form of buyer investment protection. If any business buys my software, they must have assurance that not just their data, but the whole application will be accessible to any other competent party they wish to transfer operations and upkeep to. It's one thing to transfer software and data custody, but a whole other ballgame to transfer ownership.
- All SaaS building blocks must be compact, stable, and composable.
- Rework must be designed out.
The following have been sloshing about my skull, in no particular order:
- SQLite for web backends
- Local First software and private data sovereignty
- Entity-Attribute-Value modeling
- Bitemporal data systems
- The meaning of time
- A healthy avoidance of schema migrations
- Immutability
- Idempotence (often the next-best thing to immutability, and sometimes even better)
- Concurrency (especially concurrent read/write independence)
At the end of the road, the specific choice of trying this in SQLite boils down to:
- Necessary Frugality
- Necessary Archival
- Unnecessarily Having a Smol Grug Brain
- Unnecessarily Caring Too Much
- Unnecessarily Poor Impulse Control
The end customers, in this particular case, survive largely on love and fresh air and the mercurial generosity of arts-supporting sponsors. But that fact is valid for any indie web app I make too. So the SaaS-es must be dirt-cheap to run. And I should be able to trivially power them up and down and up again.
Complete database exports must be made available, on-demand, in a universally query-able, archive-grade format. The database itself must be archive-grade. Only SQLite publicly guarantees availability till 2050. And they are one of a few formats approved by the US Library of Congress for data archival.
Because though We are one, and We are little, and We live like an artist, We care about sovereign data ownership a bit too much, especially when the Sovereign is the poor NPC at the bottom of the B2B food chain.
It must be trivial to store each customer's data in the appropriate geography. And to offer it for download on demand. And to forget it completely, when asked. And to be able to prove that we've done so.
No, we can't use automagic managed services, because that means deep vendor lock-in.
Last but not least, The Whole Thing Must be Single Operator Friendly Especially If Said Operator Will Necessarily Have To Operate Internationally, Meaning They Can Easily Run Afoul Of Data Residency and Privacy Laws That They Cannot Humanly Know Or Keep Abreast Of. Like Ever . 19
Readings and References
Research references
- Data and Reality, 2nd Edition (PDF via Hillel Wayne's endorsement).
- Temporal Database Management (April 2000), dr.techn. thesis by Christian S. Jensen.
- Developing Time-Oriented Database Applications in SQL (year 2000), Richard T. Snodgrass.
Temporal Data System Friendly Products
Consult their official documentation, blog, talks.
- Clojure by Rich Hickey, especially:
- The Value of Values - Rich Hickey (InfoQ, JaxConf 2012)
- Deconstructing the Database - Rich Hickey (InfoQ, JaxConf 2012)
- Datomic by Cognitect, especially:
- The Design of Datomic - Rich Hickey (InfoQ, Clojure/West 2019)
- XTDB by JUXT, especially:
- The Crux of Bitemporality - Jon Pither (Clojure/North 2019)
- Rama by RedPlanetLabs, especially:
- Simple ideas with huge impact from Clojure and Rama, Nathan Marz (reClojure 2025).
Affiliations / Disclosures
- I use Clojure for work and hobby software, and participate in the community.
as-of(see what I did there?) publication date, I have no commercial affiliations with any of the products or book publishers listed.
Special Thanks and Credits
A friendly generous wise needlessly self-effacing gentleman and scholar of infinite patience—you know who you are 🍻—who's simple requirement (really it's a day's worth of vibe-coding) precipitated this months long (and ongoing) detour across temporal data rabbit holes.
James Henderson and Jeremy Taylor of the XTDB team generously gave much-needed feedback and encouragement in the Clojurians Slack (see thread). Also members of the selfsame Clojurians Slack who are only too happy to have thinky-thoughts together. I visit for Clojure, but stay for #off-topic.